在本課中,我們將綜合探討最新的人工智能技術在金融領域中的應用,理解金融市場的法律與合規要求,並深入考慮AI技術在金融中的倫理問題。最後,我們將回顧整個學習過程,並制定未來的學習和發展計劃。這將幫助您全面了解AI在金融中的角色,並為未來的發展做好準備。另外部分內容會呼應到前面內容,歡迎大家回到 Day0搭配目錄~ 今日 Colab

自動化報告生成:
利用GPT生成財務報告、分析報告,提高效率。
示例:使用GPT撰寫季度財報摘要。
import openai
openai.api_key = 'YOUR_API_KEY'
prompt = """
請根據以下數據生成一份Apple公司2023年第四季度的財務報告摘要:
營收:1234億美元
淨利潤:456億美元
主要驅動因素:iPhone銷售增長、服務業務擴展
"""
response = openai.Completion.create(
engine="gpt-4o-mini",
prompt=prompt,
max_tokens=150
)
print(response.choices[0].text.strip())
客戶服務與聊天機器人:
聯邦學習(Federated Learning, FL)是一種分布式機器學習技術,允許多個參與方(如金融機構)在不共享其原始數據的情況下,共同訓練一個全局模型。這種方法在保護數據隱私和符合合規要求的同時,充分利用了各機構的數據資源,提升了模型的性能和泛化能力。在金融領域,聯邦學習具有廣泛的應用前景,以下將詳細探討其在金融中的具體應用、優勢、挑戰以及實現方法。因篇幅有限今天只會簡單介紹,聯邦學習的詳細算法還請有興趣的人可參考這個
聯邦學習的核心理念是將模型訓練過程分散到各個參與方本地進行,僅傳輸模型參數或梯度,而不涉及原始數據。具體流程如下:
這一過程保證了數據的本地性和隱私性,同時利用了分布式數據的優勢提升模型性能。
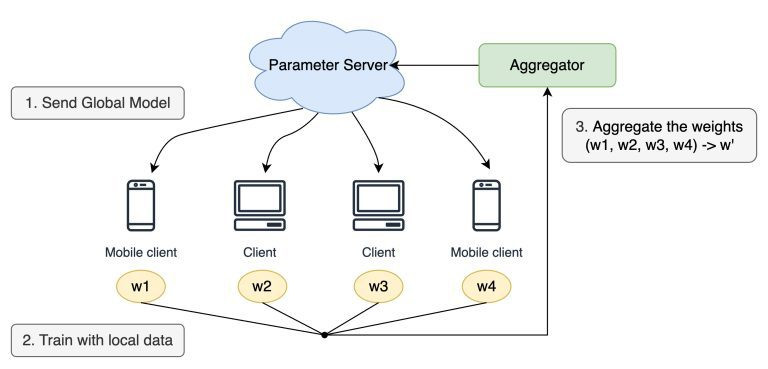
聯邦學習在金融領域的應用場景多樣,主要包括但不限於以下幾個方面:
應用說明:
信用評分是金融機構評估借款人信用風險的重要工具。不同銀行和貸款機構擁有不同的客戶數據,這些數據通常包含敏感的個人信息。通過聯邦學習,這些機構可以在不共享原始數據的情況下,共同訓練一個更加準確和全面的信用評分模型。
優勢:
實現步驟:
應用說明:
詐騙行為在金融交易中屢見不鮮,且不斷演變。不同金融機構面臨的詐騙手法各異,通過聯邦學習,這些機構可以共享詐騙行為的模型學習經驗,提升詐騙檢測系統的準確性和靈敏度。
優勢:
實現步驟:
應用說明:
投資機構依賴大量數據來制定和優化投資策略。不同機構擁有不同的市場數據和交易歷史,聯邦學習允許這些機構在保護數據隱私的前提下,共同訓練更為精確和穩健的投資策略模型。
優勢:
實現步驟:
聯邦學習在金融領域的應用帶來了多方面的優勢,主要包括:
金融數據通常包含敏感的個人信息和商業機密,聯邦學習通過在本地訓練模型,避免了數據的集中存儲和傳輸,減少了數據洩露的風險,符合嚴格的隱私保護法規(如GDPR、CCPA)。
聯邦學習允許多個數據源共同訓練模型,集成了更多樣化和豐富的數據,提升了模型的泛化能力和準確性。在信用評分和詐騙檢測等應用中,這意味著更精確的風險評估和更靈敏的詐騙識別。
通過聯邦學習,金融機構無需購買和維護大量的數據存儲和處理基礎設施,降低了數據管理的成本。同時,分布式訓練減少了數據傳輸的時間,提高了模型訓練的效率。
聯邦學習為金融機構之間的數據共享和合作提供了一種安全、有效的方式,促進了行業內的知識共享和創新。這有助於金融機構共同應對市場挑戰,提升整體行業的競爭力。
儘管聯邦學習在金融領域具有諸多優勢,但在實際應用中也面臨一些挑戰:
聯邦學習的實現需要高度協同的技術架構,包括安全的模型更新傳輸、有效的聚合算法以及分布式計算框架。這對金融機構的技術能力提出了較高要求。
聯邦學習涉及大量的模型參數或梯度的傳輸,尤其在參與方數量龐大時,通信成本和延遲可能成為瓶頸。需要優化通信協議和數據傳輸效率,減少帶寬消耗。例如可以參考這個研究
不同金融機構的數據可能具有不同的分布和特徵,這會影響模型的訓練效果。需要設計能夠處理數據異質性的聯邦學習算法,確保模型在各參與方數據上的穩定性和一致性。可以參考這個研究
儘管聯邦學習提高了數據的隱私保護,但模型參數或梯度仍可能洩
露某些敏感信息。需要引入額外的隱私保護技術,如差分隱私(Differential Privacy)和安全多方計算(Secure Multi-Party Computation),進一步加強數據的保護。
在金融領域實現聯邦學習需要考慮多方面的技術細節,以下將介紹常見的聯邦學習框架和具體實現步驟:


步驟1:需求分析與設計
步驟2:選擇聯邦學習框架
根據需求和技術能力選擇合適的聯邦學習框架,如TFF、PySyft或FATE。
步驟3:模型選擇與構建
步驟4:實施聯邦學習訓練
步驟5:模型評估與優化
步驟6:部署與監控
步驟7:維護與更新
聯邦學習在金融領域的應用,為金融機構提供了一種在保護數據隱私和符合合規要求的前提下,共同訓練高性能機器學習模型的有效方法。通過聯邦學習,金融機構可以在信用評分、詐騙檢測、投資策略優化等多個應用場景中,提升模型的準確性和泛化能力,同時降低數據管理和共享的風險。儘管聯邦學習在實施過程中面臨技術複雜性、通信效率、數據異質性等挑戰,但隨著技術的進步和行業標準的建立,聯邦學習將在金融領域發揮越來越重要的作用。
快速適應新市場或新策略:
優勢:減少模型重新訓練的時間,提升交易效率。
有興趣請參閱這個 Blog 介紹 & 這個研究
強化學習(Reinforcement Learning):
深度學習(Deep Learning):
主要監管機構與法規:
主要法規:
算法偏見(Bias):
透明性與可解釋性(Transparency & Explainability):
責任與問責(Accountability):
隱私保護(Privacy):
全部內容目錄可見於Day0~
持續學習最新技術:
實踐與項目經驗:
專業認證與進修:
關注行業趨勢:
AI在金融中的應用案例分析:
倫理與合規報告:
未來學習計劃制定:
實際應用項目:
書籍:
論文與報告:
線上資源:
監管機構網站:
通過本課的學習,應該對最新的AI技術在金融中的應用有了深入的理解,並能夠考慮和解決AI應用中的倫理與合規問題。同時,也對整個學習過程有了全面的回顧,並制定了未來的學習和發展計劃。希望這些知識和技能能夠幫助您在金融科技領域取得更大的成就。
注意:在實際應用AI技術於金融領域時,請務必遵守相關法律法規和倫理標準,並諮詢專業人士的意見,以確保技術應用的合法性和道德性。
這世界上沒有 text-davinci-004 這種東西唷,而且 text-davinci 系列在 2024/1 就已經 deprecated 啦
感謝大大~~
那我改成 gpt-4o-mini

